RBF Kernel
Class
- class kerch.kernel.rbf(**kwargs)
Bases:
exponentialRBF kernel (radial basis function).
\[k(x,y) = \exp\left( -\frac{\lVert x-y \rVert_2^2}{2\sigma^2} \right).\]- Parameters
sigma (double, optional) – Bandwidth \(\sigma\) of the kernel. If None, the value is filled by a heuristic on the sample dataset: 3/10th of the median of the pairwise distances. Computing the heuristic on the full sample dataset can be expensive and idx_sample or prop_sample could be specified to only compute it on a subset only., defaults to None.
sigma_trainable (bool, optional) – True if the gradient of the bandwidth is to be computed. If so, a graph is computed and the bandwidth can be updated. False just leads to a static computation., defaults to False
center (bool, optional) – True if any implicit feature or kernel is must be centered, False otherwise. The center is always performed relative to a statistic on the sample., defaults to False
normalize (bool, optional) – True if any implicit feature or kernel is must be normalized, False otherwise. The center is always performed relative to a statistic on the sample., defaults to False
sample (Tensor(num_sample, dim_input), optional) – Sample points used to compute the kernel matrix. When an out-of-sample computation is asked, it will be given relative to these samples., defaults to None
sample_trainable (bool, optional) – True if the gradients of the sample points are to be computed. If so, a graph is computed and the sample can be updated. False just leads to a static computation., defaults to False
num_sample (int, optional) – Number of sample points. This parameter is neglected if sample is not None and overwritten by the number of points contained in sample., defaults to 1
dim_input (int, optional) – Dimension of each sample point. This parameter is neglected if sample is not None and overwritten by the dimension of the sample points., defaults to 1
idx_sample (float, optional) – Initializes the indices of the samples to be updated. All indices are considered if both idx_stochastic and prop_stochastic are None., defaults to None
prop_sample – Instead of giving indices, specifying a proportion of the original sample set is also possible. The indices will be uniformly randomly chosen without replacement. The value must be chosen such that \(0 <\) prop_stochastic \(\leq 1\). All indices are considered if both idx_stochastic and prop_stochastic are None., defaults to None.
- property K: Tensor
Returns the kernel matrix on the sample dataset. Same result as calling
k(), but faster. It is loaded from memory if already computed and unchanged since then, to avoid re-computation when reccurently called.\[K_{ij} = k(x_i,x_j).\]
- c(x=None, y=None, center=None, normalize=None) Tensor
Out-of-sample covariance matrix.
Note
A centered and normalized covariance matrix is a correlation matrix.
- property center: bool
Indicates if the kernel has to be centered. Changing this value leads to a recomputation of the statistics.
- property current_sample: Tensor
Returns the sample that is currently used in the computations and for the normalizing and centering statistics if relevant.
- property dim_feature: int
Returns the dimension of the explicit feature map if it exists.
- property dim_input: int
Dimension of each datapoint.
- forward(x, representation='dual') Tensor
Passes datapoints through the kernel.
- Parameters
x (Tensor(,dim_input)) – Datapoints to be passed through the kernel.
representation (str, optional) – Chosen representation. If dual, an out-of-sample kernel matrix is returned. If primal is specified, it returns the explicit feature map., defaults to dual
- Returns
Out-of-sample kernel matrix or explicit feature map depending on representation.
- Raises
RepresentationError
- get_log_level() int
Returns the log Level used by this object.
- property hparams
- property idx: Tensor
Indices used when performing various operations. This is only relevant in the case of stochastic training.
- init_sample(sample=None, idx_sample=None, prop_sample=None)
Initializes the sample set (and the stochastic indices).
- Parameters
sample (Tensor, optional) – Sample points used for the various computations. When an out-of-sample computation is asked, it will be given relative to these samples. In case of overwriting a current sample, num_sample and dim_input are also overwritten. If None is specified, the sample dataset will be initialized according to num_sample and dim_input specified during the construction. If a previous sample set has been used, it will keep the same dimension by consequence. A last case occurs when sample is of the class torch.nn.Parameter: the sample will then use those values and they can thus be shared with the module calling this method., defaults to None
idx_sample (int[], optional) – Initializes the indices of the samples to be updated. All indices are considered if both idx_sample and prop_sample are None., defaults to None
prop_sample – Instead of giving indices, specifying a proportion of the original sample set is also possible. The indices will be uniformly randomly chosen without replacement. The value must be chosen such that \(0 <\) prop_sample \(\leq 1\). All indices are considered if both idx_sample and prop_sample are None., defaults to None.
- k(x=None, y=None, implicit=False, center=None, normalize=None) Tensor
Returns a kernel matrix, either of the sample, either out-of-sample, either fully out-of-sample.
\[K = [k(x_i,y_j)]_{i,j=1}^{N,M},\]with \(\{x_i\}_{i=1}^N\) the out-of-sample points (x) and \(\{y_i\}_{j=1}^N\) the sample points (y).
Note
In the case of centered kernels, this computation is more expensive as it requires to center according to the sample dataset, which implies computing a statistic on the out-of-sample kernel matrix and thus also computing it.
- Parameters
x (Tensor(N,dim_input), optional) – Out-of-sample points (first dimension). If None, the default sample will be used., defaults to None
y (Tensor(M,dim_input), optional) – Out-of-sample points (second dimension). If None, the default sample will be used., defaults to None
center (bool, optional) – Returns if the matrix has to be centered or not. If None, then the default value used during construction is used., defaults to None
normalize (bool, optional) – Returns if the matrix has to be normalized or not. If None, then the default value used during construction is used., defaults to None
- Returns
Kernel matrix
- Return type
Tensor(N,M)
- Raises
PrimalError
- manifold_parameters(recurse=True, type='euclidean') Iterator[Parameter]
- property name
Name of the module. This is relevant in some applications
- property normalize: bool
Indicates if the kernel is normalized. This value cannot be changed for exponential kernels.
- property num_idx: int
Number of selected indices when performing various operations. This is only relevant in the case of stochastic training.
- property num_sample: int
Number of datapoints in the sample set.
- property params
Dictionnary containing the parameters and their values. This can be relevant for monitoring.
- reset(children=False)
- property sample: Parameter
Sample dataset.
- property sample_trainable: bool
Boolean if the sample dataset can be trained.
- set_log_level(level: Optional[int] = None) int
Sets a specific log Level to this object. It serves as a way to use specific log Level for a specific class, different than the current general KerPy log Level.
- Parameters
level – If the value is
None, the current general KerPy log Level will be used (WARNING if not specified otherwise)., defaults toNone.type – int, optional
- property sigma
Bandwidth \(\sigma\) of the kernel.
- property sigma_trainable: bool
Boolean indicating of the bandwidth is trainable.
- stochastic(idx=None, prop=None)
Resets which subset of the samples are to be used until the next call of this function. This is relevant in the case of stochastic training.
- Parameters
idx (int[], optional) – Indices of the sample subset relative to the original sample set., defaults to None
prop (double, optional) – Instead of giving indices, passing a proportion of the original sample set is also possible. The indices will be uniformly randomly chosen without replacement. The value must be chosen such that \(0 <\) prop_stochastic \(\leq 1\)., defaults to None.
If None is specified for both idx_stochastic and prop_stochastic, all samples are used and the subset equals the original sample set. This is also the default behavior if this function is never called, nor the parameters specified during initialization.
Note
Both idx_stochastic and prop_stochastic cannot be filled together as conflict would arise.
- train(mode=True)
Activates the training mode, which disables the gradients computation and disables stochasticity. For the gradients and other things, we refer to the torch.nn.Module documentation. For the stochastic part, when put in evaluation mode (False), all the sample points are used for the computations, regardless of the previously specified indices.
- update_sample(sample_values, idx_sample=None)
Updates the sample set. In contradiction to init_samples, this only updates the values of the sample and sets the gradients of the updated values to zero if relevant.
- Parameters
sample_values (Tensor) – Values given to the updated samples.
idx_sample (int[], optional) – Indices of the samples to be updated. All indices are considered if None., defaults to None
Examples
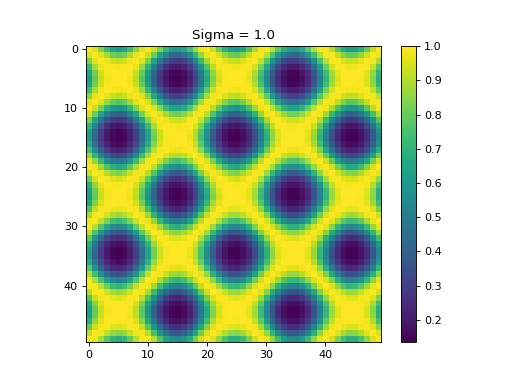
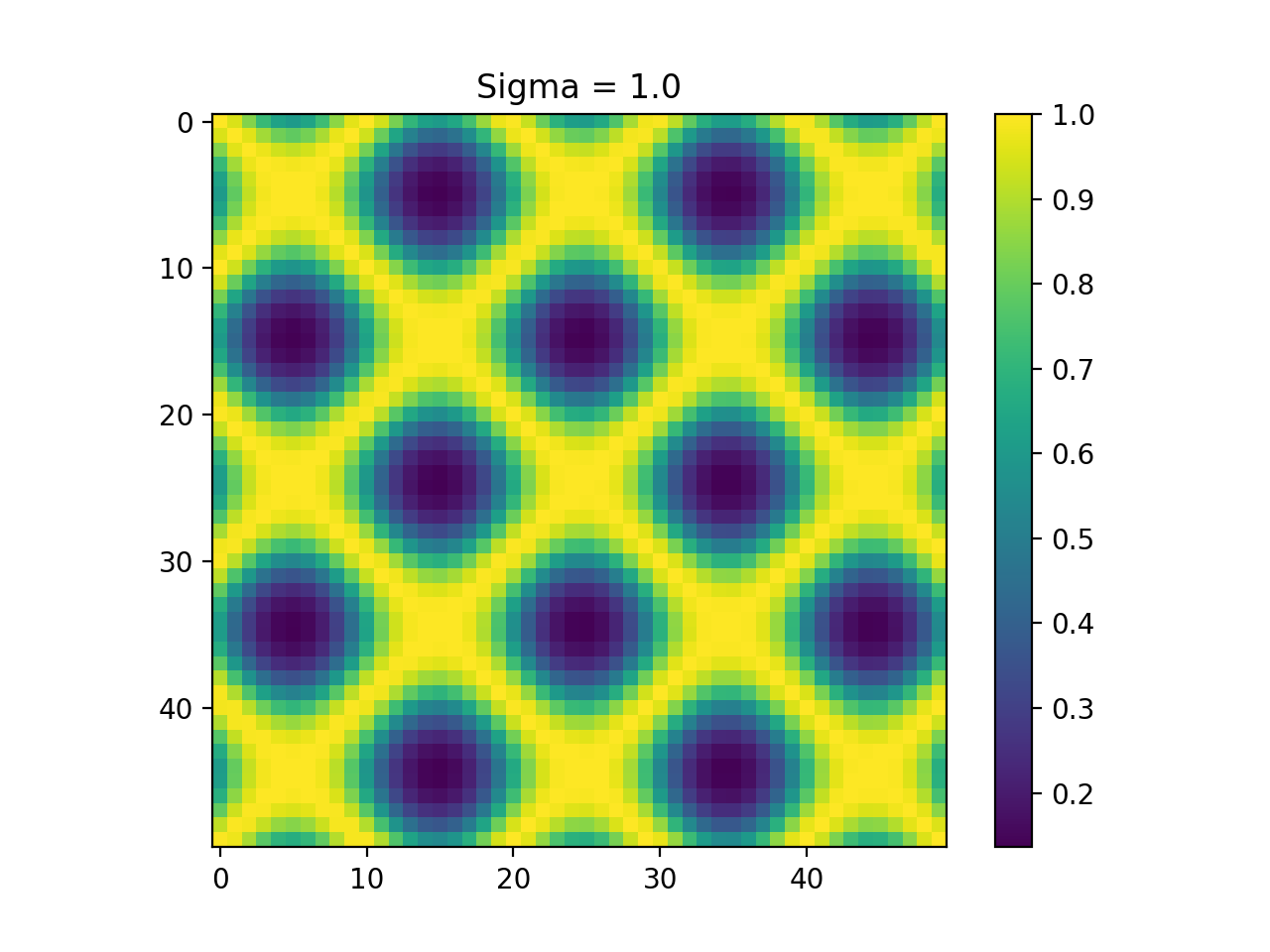
Sine
import kerch
import numpy as np
from matplotlib import pyplot as plt
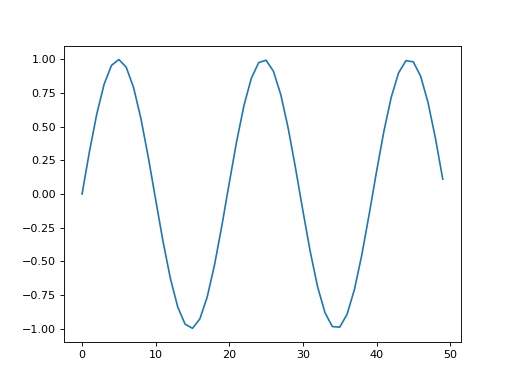
x = np.sin(np.arange(50) / np.pi)
plt.figure(0)
plt.plot(x)
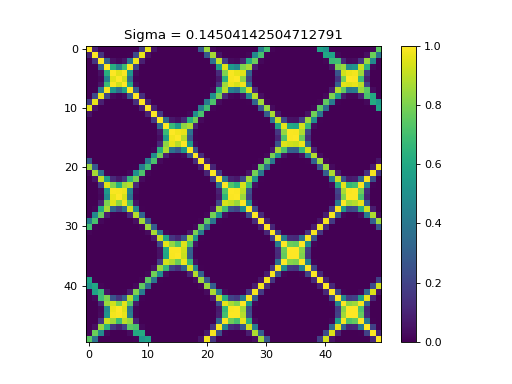
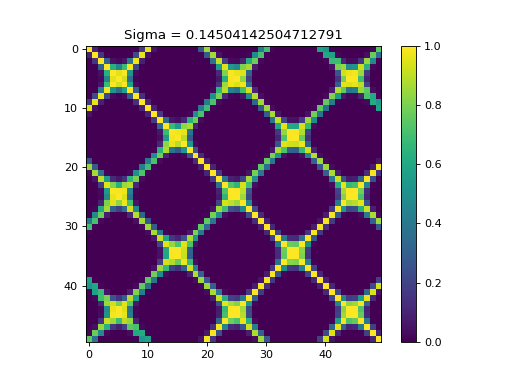
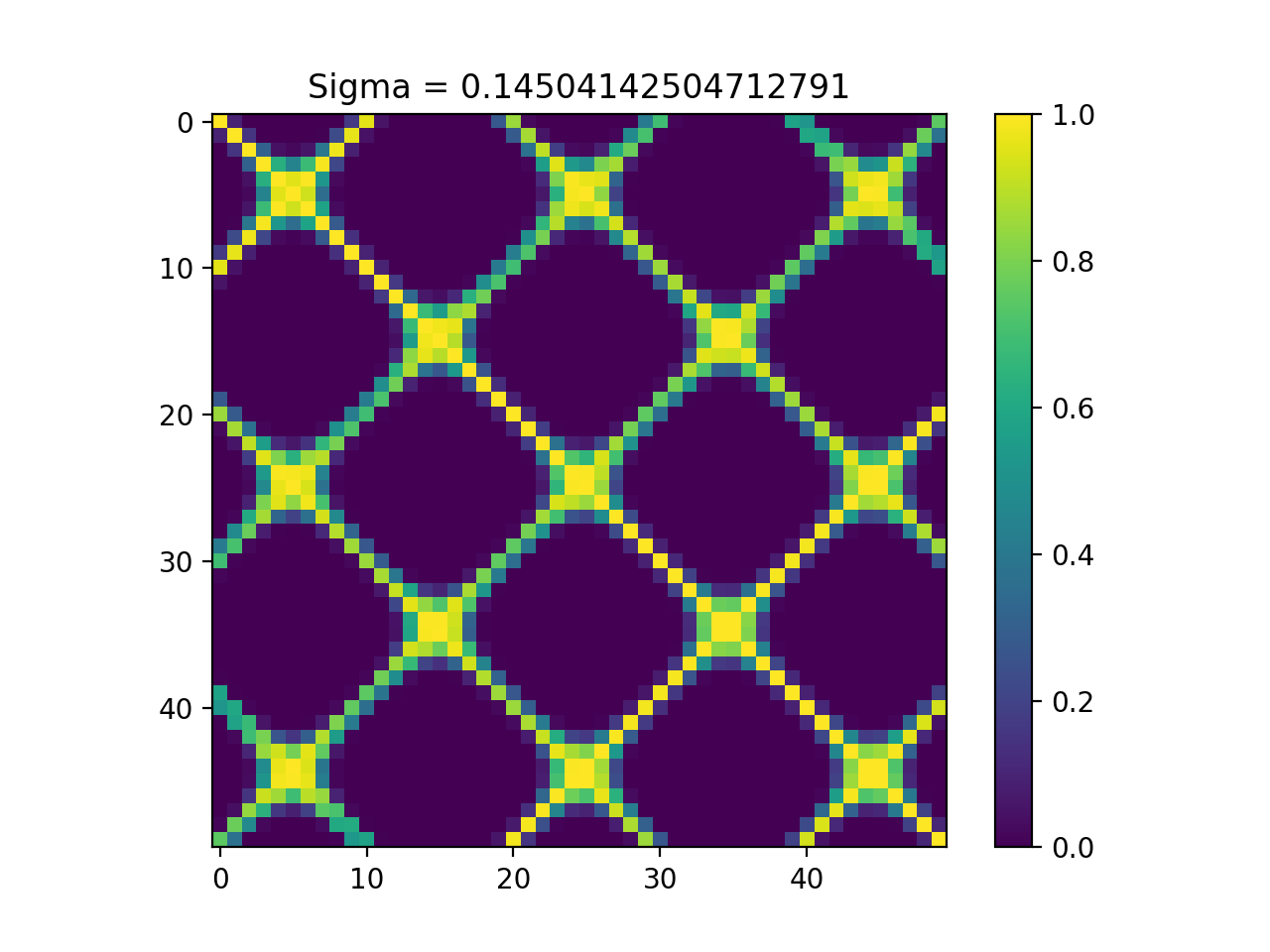
k = kerch.kernel.rbf(sample=x)
plt.figure(1)
plt.imshow(k.K)
plt.colorbar()
plt.title("Sigma = "+str(k.sigma))
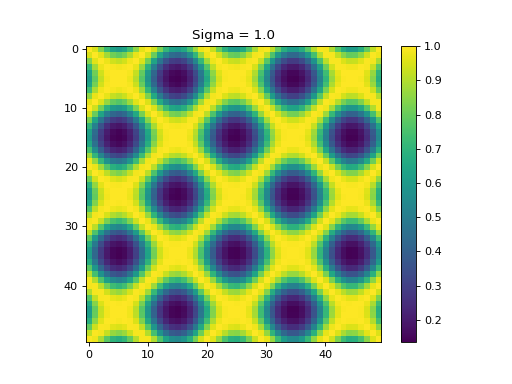
k.sigma = 1
plt.figure(2)
plt.imshow(k.K)
plt.colorbar()
plt.title("Sigma = "+str(k.sigma))
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
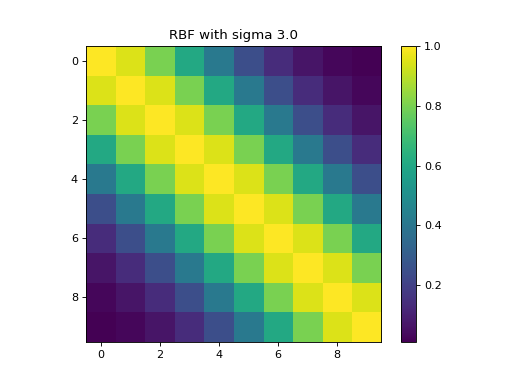
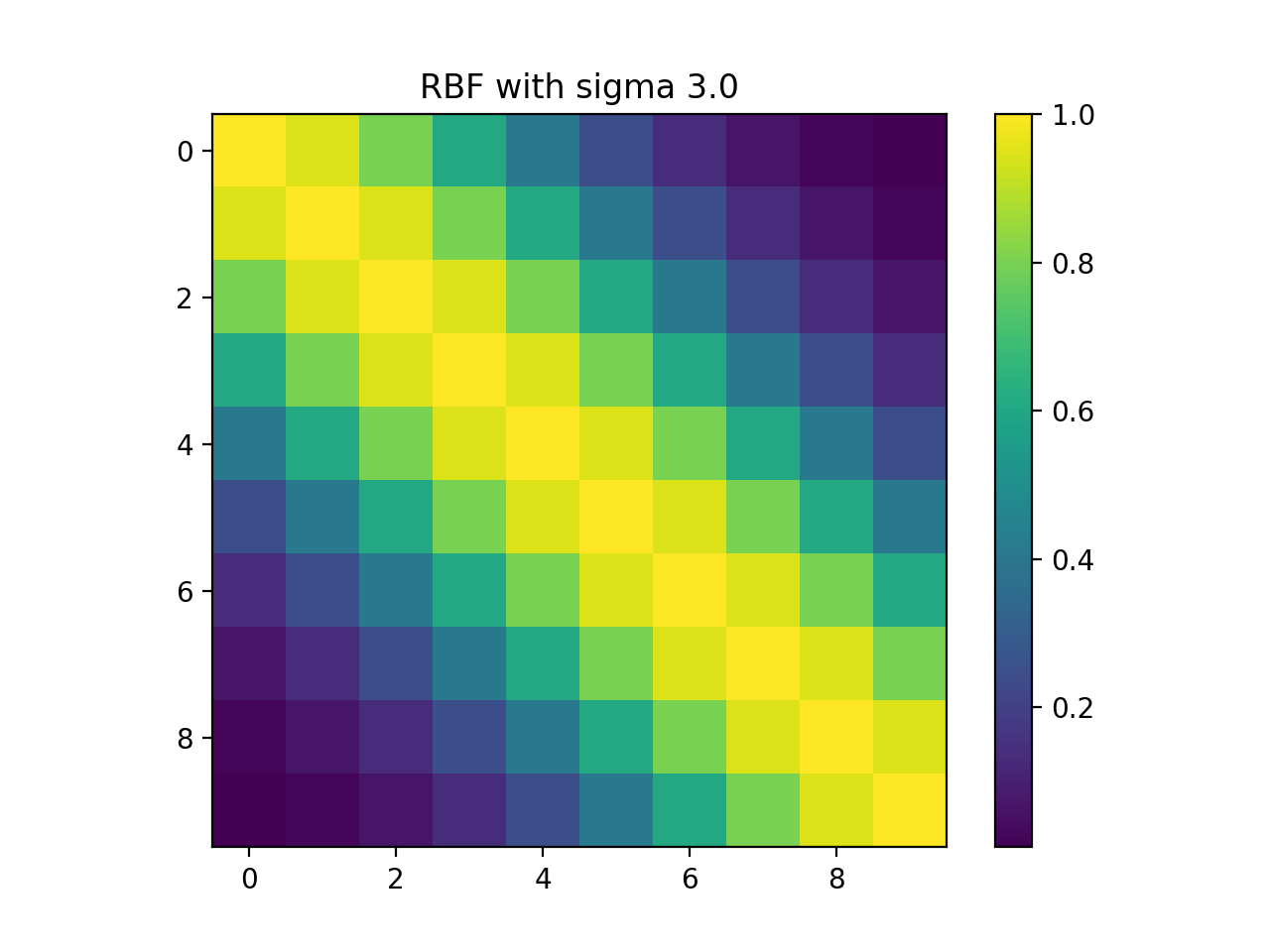
Time
import kerch
from matplotlib import pyplot as plt
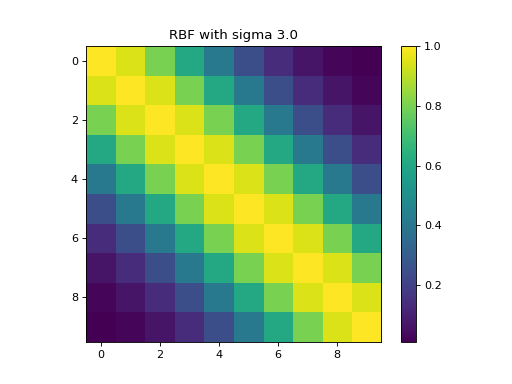
k = kerch.kernel.rbf(sample=range(10), sigma=3)
plt.imshow(k.K)
plt.colorbar()
plt.title("RBF with sigma " + str(k.sigma))
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}